02/08/2018

Google has a new logo and updating its image – but under the surface it’s still that pre-2010 half-evil censor
Eight years after Google pulled out of the censored Chinese internet, they’re back. It’s been reported that the company is working on a mobile search app that would block certain search terms and allow it to reenter the Chinese market.
Google has engaged in the China-controlled internet space before: but in 2010 it pulled out, citing censorship and hacking as reasons. It didn’t pull out completely – it still offered a number of apps to Chinese users, including Google Translate and Files Go, and the company has offices in Beijing, Shenzhen and Shanghai – But the largest of its services – search, email, and the Play app store – are all unavailable in the country.
Google co-founder Sergey Brin told the Guardian in 2010 that his opposition to enabling censorship was motivated to his being born in Soviet Russia. “It touches me more than other people having been born in a country that was totalitarian and having seen that for the first few years of my life,” he said as Google exited the Chinese market after 4 years of cooperating with the authorities.
But now they’re back, working on a mobile search app that would block certain search terms and black-listed material. The app is being designed for Android devices.
According to tech-based news site The Information, Google is also working on a censored news-aggregation app too. The news app would take its lead from popular algorithmically-curated apps such as Bytedance’s Toutiao – released for the Western market as “TopBuzz” – that eschew human editors in favour of personalised, highly viral content.
Patrick Poon, China Researcher at Amnesty International, called Google’s return to censorship “a gross attack on freedom of information and internet freedom.”
In putting profits before human rights, he said, Google would be setting a chilling precedent and handing the Chinese government a victory.
This is important because many computer users will set a search site as their homepage and even find content by entering key-words into the url bar of their browser. Because of Google’s ubiquity, it is frequently set as default search engine on browsers, meaning that millions of users will find that their experience of the internet is that delivered through the lens of Google. If that lens is smudged or cracked by censorship, all these users’ internet experience is skewed. So it is essential to highlight the fact that Google is not the neutral, trustworthy agent that many users think it to be.
GreatFire, an organisation that monitors internet censorship and enables circumvention of the “Great Firewall of China”, said the move “could be the final nail in the Chinese internet freedom coffin” and that “the ensuing crackdown on freedom of speech will be felt around the globe.”

 Leave a Comment » |
Leave a Comment » |  censorship, China, computers, free, google, hacking, internet, OMG, politics, technology | Tagged: censorship, China, computers, democracy, dictatorship, dissent, dissident, free speech, freedom, google, great firewall of china, greatfire, hacking, internet, police state, search, technology, World Wide Web |
censorship, China, computers, free, google, hacking, internet, OMG, politics, technology | Tagged: censorship, China, computers, democracy, dictatorship, dissent, dissident, free speech, freedom, google, great firewall of china, greatfire, hacking, internet, police state, search, technology, World Wide Web |  Permalink
Permalink
 Posted by Martin X
Posted by Martin X
20/07/2018
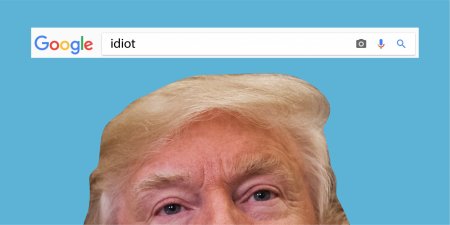
Don’t wanna be an american idiot? Too late Donald!
Ain’t it grand, how any idiot can game Google results and show the world who really is the idiot?
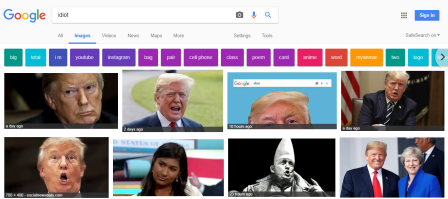
That’s what activists have been doing: do a Google image search for the word “idiot” and you get a fine selection of Donald Trump pictures!
This is how it works:
According to Inquisitr, part of the reason for this result is that several English articles published last week included the Green Day song titled “American Idiot” in the headline in relation to Donald Trump and his trip to England; (protestors were actually using the song in the protests). This meant that images were likely titled to describe the article and used the terms “American Idiot” and Donald Trump as descriptives in the image metadata as well as in the article content. As a result, Google’s algorithm has paired these terms together, and with so many people reading and sharing these articles, it has pushed its relevance to the top of the search results.
When you type the word “idiot” into Google’s image search, Trump is the first returned result. This is partly because the Green Day song American Idiot was used by protesters to soundtrack his trip to London. But since then there’s also been a concerted campaign to capitalize on that association, and manipulate Google’s algorithm, by linking the word to the picture. Mostly this involved people upvoting a post containing a photo of him and the word “idiot” on Reddit. [from theguardian.com]
This trick has been used many times before. For instance, there was a spate of hook-nosed caricatures posted with the single word “Jew”, which resulted in an Image Search for “jew” returning the hook-nosed caricature.
And it was used by Trump fans to associate the word “rapist” with pictures of Bill Clinton.
Many of these were rudimentary, almost meaningless. “RAPIST! RAPIST! RAPIST! RAPIST!” “Today this rapist turns 70. Happy Birthday, rapist.” Most originated from the notorious Reddit forum TheDonald, where fans of Trump congregated to spread his gospel of doing whatever you like, screw the consequences.
The forum moderators would pin a post to the top of the forum to encourage others to upvote it, and the swell of upvotes would push it to the front page of Reddit, which already styles itself “The front page of the Internet”, causing it to leap up to the top row of Google images.
They also did it with an image of Michelle Obama with features Paintshopped to look like an ape. And the TheDonald team did it with the CNN logo and the words “fake news”.
So it’s kind of fitting that the trick has now been turned on Trump and his idiotic fans!
So is there a moral to be learnt from this story? Of course not! The internet is utterly amoral, as are those of us who spend too much time in it. Who knows who will be belittled and demonized next? And that’s probably the best thing about it – he who demonizes today may be demonized tomorrow. The internet giveth and… well, it don’t giveth anything but it demands its pound of virtual flesh!
Leave a Comment » | An American Idiot, Donald Trump, Green Day, idiot, London, OMG, Trump, UK, US/UK, USA | Tagged: american idiot, Donald Trump, google, Green Day, idiot, internet, London, Trump, UK, USA | Permalink
Posted by Martin X
16/07/2018

Rolls-Royce EVTOL air taxi concept, launched at Farnborough Air Show July 2018
People have been dreaming of personal flying vehicles since Icarus flew too close to the sun. But there have been fundamental problems to the concept of air taxis and flying “cars”: noise, pollution and the need for air strips included. But now the technology to make the dream possible has arrived: EVTOL.
Electric (or hybrid-electric, or electrically-assisted) Vertical Take-Off/Landing means an air vehicle that has the VTOL characteristics of a helicopter but otherwise flies like a fixed-wing airplane. The VTOL is possible thanks to swivel-wings or swivel engines that are electrically (or hybrid-electrically) powered. This helps beat the noise problem of helicopters, the pollution that a high concentration of conventionally-fuelled aircraft would cause, and the urban airstrips that fixed-wing vehicles would need.
For example, let’s look at the EVTOL air taxi concept that Rolls-Royce unveilled earlier today (16 July 2018) at the Farnborough Airshow. The hybrid aircraft, designed to carry four or five passengers, has an M250 gas turbine which delivers around 500kW of electrical power. This is used to drive six rotors that can provide both lift and propulsion, with the wings tilting forward 90 degrees once sufficient altitude has been reached. Four of the rotors can also fold into the wings, leaving two at the rear to provide thrust at cruising altitude while helping to reduce cabin noise. Top speed is estimated at 250mph and range is predicted to be 500 miles. According to Rolls, an onboard battery will bring additional climb power and will be recharged by the M250 engine.
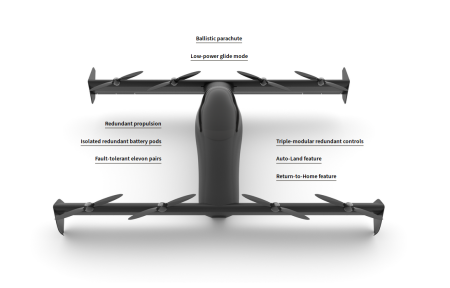
The Blackfly Personal EVTOL
And this is just four days after Opener announced its single-person EVTOL personal aerial vehicle, Blackfly, hailed as the world’s first ultralight, fixed-wing EVTOL aircraft. The BlackFly Opener is amphibious and is primarily designed as a small grassy area hopper. It can travel up to 25 miles at 62 mph in the US, or over 80 mph elsewhere. And in the US anyone can own and operate a Blackfly – there is no need for formal licensing. And in the pollution stakes: it uses less energy than an electric car, and produces less noise than do petrol-driven cars.
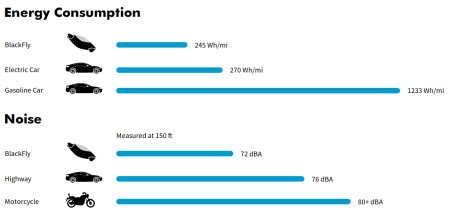
How the Blackfly stacks up on the noise and energy fronts
Unlike Opener, Rolls-Royce produced a concept rather than an actual aircraft. Nevertheless they claim that the concept is based upon technology that either already exists or is currently under development. If a viable commercial model emerges, the company believes the vehicle could be in service by the early 2020s. However there will be a lot of competition in this market: Airbus and Uber have both announced plans, Google’s Kittyhawk is taking orders ; and last year, Dubai staged its first autonomous air taxi trial, and authorities there claim personal air mobility could transform the region over the next five years.
In April 2017 after the first Uber Elevate Summit, Electric VTOL News started a catalogue of EVTOL aircraft – it grew at a rate of about one aircraft per week during the first year, but this has now accelerated to an average rate of two aircraft per week as more aircraft are unveiled and new actors join the sector, and now numbers over a hundred aircraft.
As of June 15, 2018, the site had 45 vectored thrust aircraft listed; 12 lift + cruise configurations; 24 wingless multicopter aircraft; and 23 Hover Bikes/Personal Flying Devices.
In addition, the website now hosts more than 100 news articles and in-depth stories on eVTOL aircraft and developments.
This is an exciting sector and brings ever closer to reality the dream of personal air vehicles – your very own airplane! So keep an eye on the skies!

Leave a Comment » | air-taxi, Airbus, autonomous, Blackfly, EVTOL, google, OMG, Rolls-Royce, technology, transport, Uber | Tagged: air-taxi, Airbus, autonomous, Blackfly, dubai, EVTOL, google, Rolls-Royce, technology, transport, Uber | Permalink
Posted by Martin X
13/07/2018
Part One of an occasional series of hateful images.

Leave a Comment » | google, google images, I HATE HATE, i hate hate images, I Hate Hate!, images, OMG | Tagged: google, google images, i hate hate images, I Hate Hate!, images | Permalink
Posted by Martin X
19/06/2018
On 20 June 2018, less than 24 hours from now, the European Parliament votes on whether to adopt the Directive on Copyright in the Digital Single Market – a $60 million filter to automate takedown of copyrighted material from Youtube. This is a compromise measure that no one really wants:
Big rightsholders say that it still lets crucial materials slip through the cracks. Indie rightsholders say that it lets big corporations falsely claim copyright over their works and take them down. Google hates Content ID because they spent $60,000,000 developing a system that makes everyone miserable, and YouTubers and their viewers hate it because it overblocks so much legit content.
But all of this has escaped the EU’s notice. Under Article 13 (which will be voted up or down in a key committee on June 20), every EU platform will be obliged to filter everything users post — not just videos, but stills, audio, code, games, text, everything.
No filter exists that can even approximate this, and the closest equivalents are mostly run by American companies, meaning that US Big Tech is going to get to spy on everything Europeans post and decide what gets censored and what doesn’t.
But we can stop it, by contacting the members of the committee and telling them what a mistake it would be to vote for the Directive. You can tweet and email the committee members using this online tool.
So if you want to automate internet censorship and destroy the creative media, do nothing. But if you’re not a colossal idiot, contact the MEPs and tell them to vote against Article 13.

Learn more about Article 13
Contact the MEPs




Leave a Comment » | Article 13, copyright, Directive on Copyright in the Digital Single Market, Europe, European Parliament, European Union, OMG | Tagged: Article 13, copyright, Directive on Copyright in the Digital Single Market, EU, European Parliament, European Union, google, YouTube | Permalink
Posted by Martin X
11/06/2018
In the wake of employee resignations and protests against their tech being used in military drone strikes, Google has reaffirmed its aspiration “Don’t Be Evil.”
Sundar Pichai, CEO at Google, has released a set of ethical guidelines to govern the company’s use of Artificial Intelligence. These new rules ban the development and use of their AI for weapons, and for surveillance tools that would violate “internationally accepted norms.”
For nearly 20 years, Google had the mantra “Don’t Be Evil” in its corporate code of conduct. But it dropped the motto in April or May of this year (2018), which made some commentators (well, me anyway) wonder if Google had decided to actively Be Evil? This thought was reinforced when a number of employees resigned over the company’s involvement in a controversial military drone pilot program, Project Maven.
But don’t worry! Google may help US military AIs recognise and classify targets, but it won’t have anything to do with killing those targets that it has labelled as “Bad Guy #1”. But how does the company square this with bidding for the Joint Enterprise Defense Infrastructure contract? (I know, I know… JEDI isn’t a “weapon”. Screw your sophistry and semantics!) As for refusing to develop “surveillance tools that would violate ‘internationally accepted norms'” – what the hell does that mean anyway? “Internationally accepted” by whom? North Korea? Saudi Arabia? Syria? Myanmar? Can you see the problem here?
So okay, Google isn’t being run by Doctor Evil. But how many Mini-Me clones are working in Research & Development?

Sundar Pichai, CEO at Google. pic from Wikipedia



Leave a Comment » | artificial intelligence, Dr Evil, google, OMG, Sundar Pichai | Tagged: ai, artificial intelligence, Dr Evil, google, jedi, Sundar Pichai | Permalink
Posted by Martin X
16/07/2014
So people who have done dodgy crap in the past have a “right to be forgotten”… meaning Google, Bing, etc have to delete links to stories about what crooks and conmen have got up to in the past. Basically, Google etc have to delete links to online stories that might “damage the reputation” of people who have done stupid and even criminal things they’ve done in the past.
But as Dan Gillmor has pointed out in the Guardian, it’s basically a charter for crooks and idiots to hide their stupidity and criminal actions, censoring their past so it looks like they’re not idiots or crooks… info that potential employers, new acquaintances and the like could well need to know. Are you going to enter into business with someone whose ineptness or criminal behaviour is public knowledge? Probably not. But now people will be employing unsuitable people.
But what’s funny about this charade is the fact that the “right to be forgotten” by Google will mean other news outlets will report on these secretive idiots. Check out the story on Robert Daniels-Dwyer. He wanted Google to remove links to reports that he was was convicted of trying to steal £200 worth of Christmas presents from Boots in Oxford in 2006. Google removed the links… but the Oxford Mail’s editor, Simon O’Neill, argued that it is “an assault on the public’s right to know perfectly legitimate information,” and Dwyers’ naughty past has been re-publicised far more than it would have been before the ruling! The Oxford Mail’s editor, Simon O’Neill, argued that it is “an assault on the public’s right to know perfectly legitimate information.”
Check out the original Oxford Mail story here. If the idiot had kept his gob shut, no one would have known about it… it was in 2006 for goodness’ sake!
Calling it a “right to censorship”, editor O’Neill continued: “It is an attempt to re-write history… We often get complaints from convicted criminals that publishing stories about them invades their privacy or is unfair but the simple fact is if they didn’t go out committing crime and appearing in court then there would not be a story.”
The Guardian reported:
The paper reported that Daniels-Dwyer had previously attempted to have the story removed from the Mail’s websites via a complaint to the Press Complaints Commission.
He demanded that Newsquest “should purge the article from all databases, internally and externally available, and from any news databases to which it provides content.”
Two factual amendments were made to the article, but the PCC dismissed his case.
If Daniels-Dwyer was the complainant to Google then it has rebounded on him because the 2006 story has got renewed, and extra, publicity – a direct consequence of all such complaints about online coverage (see the Streisand effect).
The right to be forgotten could well turn out to be the right to be remembered.
So it looks like Daniels-Dwyer has well and truly screwed himself! Ha ha ha!!


Leave a Comment » | Boots, censorship, crime, Daniels-Dwyer, idiotic, Robert Daniels-Dwyer | Tagged: censorship, crime, freedom of expression, google, Oxford Mail, right to be forgotten, Robert Daniels-Dwyer, Simon O'Neill | Permalink
Posted by Martin X
17/06/2014
The British government has for the first time spelt out why it thinks it has the right to snoop on our Google, Facebook and other internet traffic all it wants.
Charles Farr, the Director General of the Office for Security and Counter Terrorism, has made a statement (available here) that claims according to UK law the security services only need to get warrants to snoop on communications from one UK party to another. Traffic to and from services like Google (which includes Gmail) and Facebook are classed as “external communications”, for which no warrants are required.
This is horrendous. The internet is a network of networks, many of which are in other countries. So a large amount of our online activity will be transferred via networks in the USA and other countries even if the activity is practically domestic. If you send an email via Gmail to another UK citizen, the government classes it as an “external communication”. The same will be true of activity on Facebook, Twitter, and a great many other services, even though your intention is to communicate or share with other UK residents. Tempora, the program run by the British snooping agency GCHQ, gathers data and metadata, then shares it with the NSA. This means that practically all our online activities are stored, and can be used in fishing expeditions, even though GCHQ or NSA do not suspect you of any potentially criminal activity. Tempora is a “buffer” which stores internet data for 3 days and metadata for 30 days. GCHQ’s computers sift through all this data, storing anything that is “of interest”, which means that online privacy really is nonexistent. Which is what many of us have assumed for ages (especially after Edward Snowden’s revelations), but now it’s official.
What really exasperates me is that major criminals and terrorists will be taking steps to avoid this already, for example by using a VPN (Virtual Private Network). The real victims of GCHQ’s activities are us ordinary joes who are not engaged in criminal conspiracies but who want privacy (like people who send letters in sealed envelopes rather than postcards). We could encrypt our communications; but how many of us want to do this? and I’ll bet Tempora looks out for encrypted traffic and logs it as suspect.
The law needs changing. But that’s not going to happen. Why would the government give up these powers? So, I’m going to use my VPN account when I go online, and I advise everyone else to do the same. Tempora’s alarms will be set off by my suspicious activity; but if everyone is doing it GCHQ’s systems will overload. I hope. Remember, GCHQ has supercomputers and massive storage facilities. Big Brother, man! 1984 man!
1 Comment | 1984, anonymity, big brother, civil liberties, facebook, freedom, freedom of expression, freedom of information, GCHQ, Gmail, google, human rights, NSA, privacy, Snowden, TEMPORA | Tagged: 1984, big brother, Edward Snowden, facebook, GCHQ, gmail, google, privacy, Snowden, TEMPORA | Permalink
Posted by Martin X
11/04/2014

Tory MP Nigel Evans. Not a rapist, historic or historical…
I’m a tad confused by the way the media is using the terms “historic” and “historical”. If we turn to wise Google and ask it to define:historic, it tells us:
famous or important in history, or potentially so.
“the area’s numerous historic sites”
synonyms: famous, famed, important, significant, notable, celebrated, renowned, momentous, consequential, outstanding, extraordinary, memorable, unforgettable, remarkable, landmark, groundbreaking, epoch-making, red-letter, of importance, of significance, of consequence, earth-shaking, earth-shattering
whereas define:historical produces:
a. Of or relating to the character of history. b. Based on or concerned with events in history. c. Used in the past: historical costumes
So something like the Potsdam conference, for instance, would be called historic, whereas the false rape allegations against Tory MP Nigel Evans would be historical. Right?
Well, I thought it was pretty simple. But then we see in the Guardian that the Evans rape allegations are called “historic allegations”. WTF? Google just told me…
So, what is it? Historic or historical? Some folk might think me mad using the Grauniad to argue such a point. But it ain’t just them: historic and historical seem to have become interchangeable terms so far as the papers are concerned. At least, that’s how it appoears to me…
Please, if anyone can explain wtf is going on, tell us in Comments. Serious and ridiculous explanations are equally welcome. Someone must know what’s going on in the editors’ heads, right? Right?
1 Comment | Conservative Party, Conservatives, historic, historical, Nigel Evans, rape, rape allegations, rapist, Tories | Tagged: Conservative, google, historic, historical, Nigel Evans, rape, rape allegations, tory, Tory MP Nigel Evans | Permalink
Posted by Martin X
13/05/2010
This is part 5 of my guide to searching the internet. Here are links to:
Part 1: History of internet search;
Part 2: How a modern web search site works;
Part 3: How to actually use a modern search engine
Part 4: How to understand the results you get from using a modern web search
I covered basic use of operators in part 3. But the proper use of operators is very important if you want to get the most from a search engine, especially if the search is at all complicated. So I’m going to go into more detail on the subject here. I got much of the info from other sites, especially www.GoogleGuide.com. But I (rather modestly) think that i present the info in a much more readable and usable form.
Okay, here we go. Operators are special uses of certain words or combination of words that mean more to the search engine than the plain use of words as simple search terms. Here’s a quick example, which you may find familiar if you’ve ever learned how to use Google to find mp3 files: Let’s imagine we want to find mp3 files of tracks by the excellent early British punk band The Clash. What we actually find are listings of the contents of directories that contain the mp3 music files. So, we could use Google search terms like this:
intitle:index.of mp3 “the clash” -.html -.htm
Let’s examine that bit by bit. It starts with intitle:index.of. The intitle part tells Google to look in the title of a page for a particular word or phrase. In this instance, the phrase to look for is index.of (which would, incidentally, look for titles that include the string “index.of” and “index of” (ie with a space rather than a period). That’s how Google and most (all?) other modern search engines work. The reason for looking for a page whose title includes the phrase “index of” is that a web page listing the contents of a directory will very likely have a title containing those words. It’s also looking for the word mp3 and the phrase “the clash”. You’ll notice we used quotation marks around “the clash”. This is my personal preference: the band was called The Clash, so I want results that contain that band name. Some people disagree, thinking that cuts out a lot of relevant results. And it’s true that some webmasters may have used the word “clash” in the page title. But I think using the word “clash” would pull up lots of irrelevant results like “Clash of the Titans” and “clash of two cultures”. So I stick with the phrase “the clash”. Whether you go with my suggestion or not is up to you.
The last 2 operators in this search are -html and -htm. You see, we’re looking for a page that lists the contents of a directory. This is not a page that is destined to be viewed by site users – it has more of a “housekeeping” function. And as it isn’t meant to be viewed by general users, it is very unlikely to contain mark-up. We’re not looking for marked-up pages; so we don’t want pages whose titles are suffixed .htm or .html. That – operator means the same as the NOT operator.
So, that was just a quick example of how operators are used to help construct a search term. Now let’s have a look at what operators are available to a search engine user:
city1 city2: this will look for info on flights from city 1 to city 2. We don’t use the actual names of the city though, we use the 3-letter airport codes. For instance, the search sfo bos will pull up times and info on flights from San Fransisco; whereas the search san fransisco boston pulls up some flight info but also a lot of unrelated results. You can find the 3-letter codes for airports worldwide here.
Here’s some more stuff about advanced Google search operators (with thanks to GoogleGuide.com):
allinanchor:
If you begin your query with allinanchor: Google restricts results to pages containing all query terms you specify in the anchor text on links to the page. Example: the query allinanchor: best museums birmingham will return only pages in which the anchor text on links to the pages contain the words best, museums and birmingham.
Anchor text is the text on a page that is linked to another web page or a different place on the current page. When you click on anchor text, you will be taken to the page or place on the page to which it is linked. When using allinanchor: in your query, do not include any other search operators. The functionality of allinanchor: is also available through the Advanced Web Search page, under Occurrences.
allintext:
If you start your query with allintext:
Google restricts results to those containing all the query terms you specify in the text of the page. For example, allintext: travel packing list will return only pages in which the words “travel”, “packing” and “list” appear in the test of the page. This functionality can also be obtained through the Advanced Web Search Page, under Occurrences.
Leave a Comment » | advanced operator, bing, computers, google, internet, internet search, operator, search engine, tutorial, Yahoo | Tagged: advanced operators, bing, computer, google, operators, search engine, tutorial, Yahoo | Permalink
Posted by Martin X

